




Project Background
Elinext was contacted by an analytical agency from Poland and was asked to create a sentiment analysis software that would analyze emotions in Polish tweets about the elections. The client wanted to download tweets by keywords (for ex: the name of a party) and evaluate the emotional reaction on a party and its key players over a certain period of time (day, week, month, etc.). Also, the client wanted to be able to identify certain words of Twitter users that could characterize a party’s activity. In this way, the analytical agency would be able to get a better understanding of what forms a party’s ranking: what should be done to improve it and what should be avoided (events, actions, words, connections, etc.).
Challenges
Elinext teams faced a challenging task to develop a solution that would allow sentiment analysis in Twitter, providing our client with the ability to receive insightful information on how Twitter users react to certain politicians, their actions, speeches, etc., and then act accordingly.
Project Description
The project outsourced to Elinext was divided into the following segments of the tweets analysis process:
- Getting Data
- Preparing Data
- Analyzing Data
Each of these steps involved different technologies and approaches described further below.
Development Process
As we already mentioned, the development process was divided into three main stages:
Getting Data
Our development team ensured that the software under development is connected to Twitter. Right after, we extracted tweet objects of our client’s interest (by certain keywords and required time intervals), so our solution would be used on a regular basis and allow getting insights into the dynamics of political preferences in Poland during and after elections. It was created to be an everyday tool for Polish political analysts.
Preparing Data
We took advantage of JSON and Pandas to transform extracted tweet objects. To prepare the tweets for their further analysis, we set up a process that excludes words that have no real semantic value (prepositions, interjections, etc.) and separates references to other Twitter accounts.
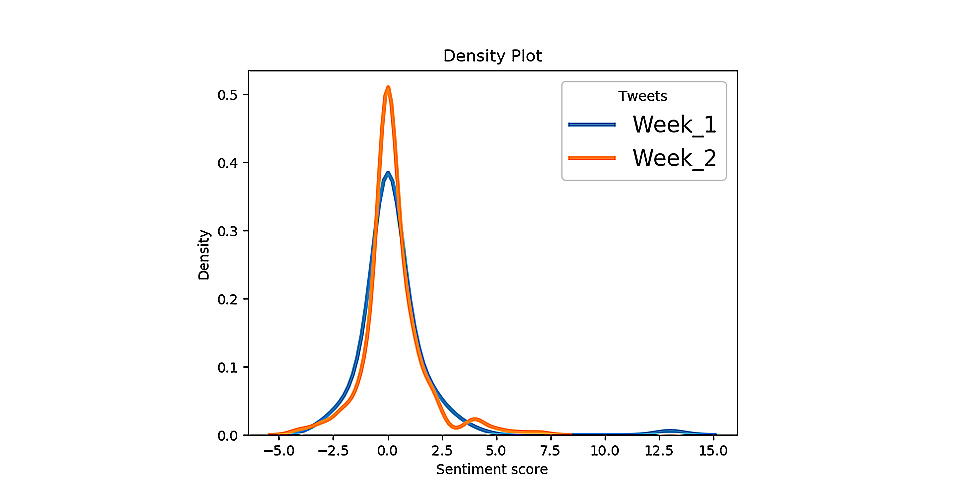
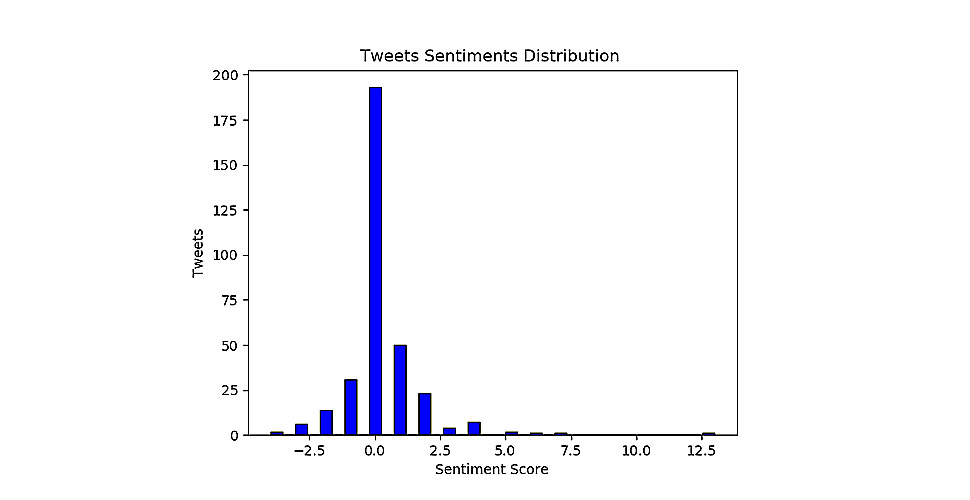
Analyzing Data
To ensure effective analysis of the remaining text, two dictionaries were used: National Corpus of Polish presented in Google’s word2vec format and PLWordnet. The first one allows Natural Language Processing (NLP) with vector representation for the Polish language dictionary. This was based on word positions in vast amounts of texts. The second includes dictionaries of Polish words with positive and negative connotations.
- National Corpus of Polish dictionary was read with Gensim library to get word2vec model.
- PLWordnet dictionary is downloadable as XML-file which was parsed with the ElementTree XML API and filtered with regular expressions.
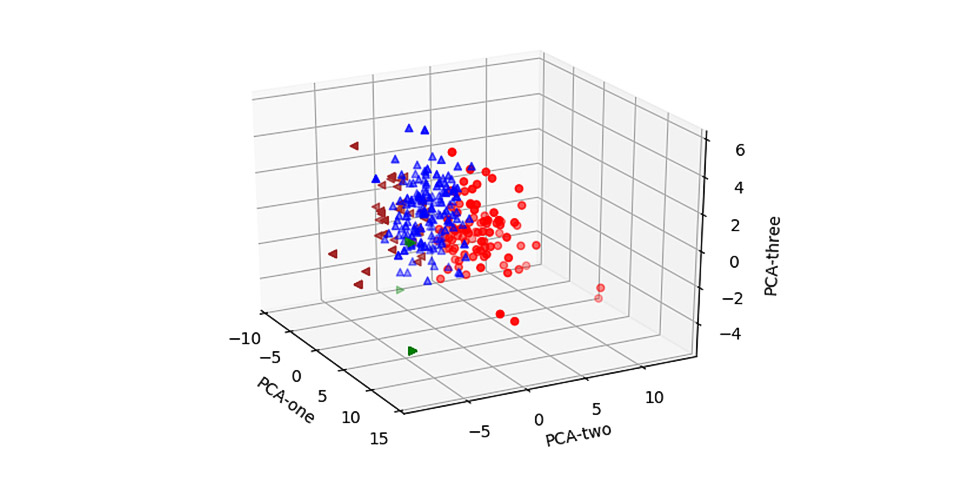
In order to reveal the clusters of the Polish electorate, the tweets cluster analysis was added. To provide a clear representation of the analyzed data, we added a data visualization option of clusters in 2d and 3d that was based on PCA dimensionality reduction technique.
Technologies
- Python
- Keras
- Pandas
- NumPy
- Tweepy
- JSON
- Gensim
- Morfeusz
- Scikit-learn
- Matplotlib
Features
- Tweets extraction by keywords, time intervals, etc.
- Tweet object transformation into JSON and Pandas data frames
- Generation of analysis outputs in .csv and .xls formats
- Text cleaning from words without semantic burden (prepositions, interjections, etc.), stop words, text tokenization
- Natural Language Processing
- XML-file parsing and strings filtering with regular expressions
- Text-to-vector transformation tweets cluster analysis
- Dimensionality reduction with Principal Component Analysis
- Data visualization
- Identification of the most frequently used words with their transformation to the initial form
- Identification of words as the parts of speech
- Calculation of frequency of occurrence in tweets and average sentiment scores for all verbs and nouns (common and proper names separately), and Twitter accounts mentioned in tweets texts (e.g., Twitter accounts of politicians)
- Identification of Twitter audience’s positive or negative attitude towards some party, politician, event, etc.
Results
Elinext team successfully created a software solution that quickly performs analysis of tweets in line with certain criteria, providing the client with insightful information based on the sentiment analysis. With the help of our software, the Polish analytical agency can understand the public attitude towards political parties, their leaders or players, their speeches, or some events. With the received information, it is possible to find out which actions or words form the public attitude, as well as to see which words or phrases used by Twitter users are linked to some party or its player, and take appropriate actions and measures to improve the image. It is worthy of mentioning, that despite being useful in politics, our software solution can also work for marketers, retailers, sociologists, and other professionals working with people’s opinions.
Harnessing Technology for Smarter Social Media and Content Engagement
Hashtag Barometer Allin1Social – SMM Platform Location-Based Social Network App Trendify App Revenue Analysis App for YouTube Content Creators Music Streaming App Hate Speech Detector and FAQ Chatbot KartinaTV