





The article will elaborate on the phenomenon of MLOps solutions and their respective life cycle and best practices. Let’s move on!
What is MLOps?
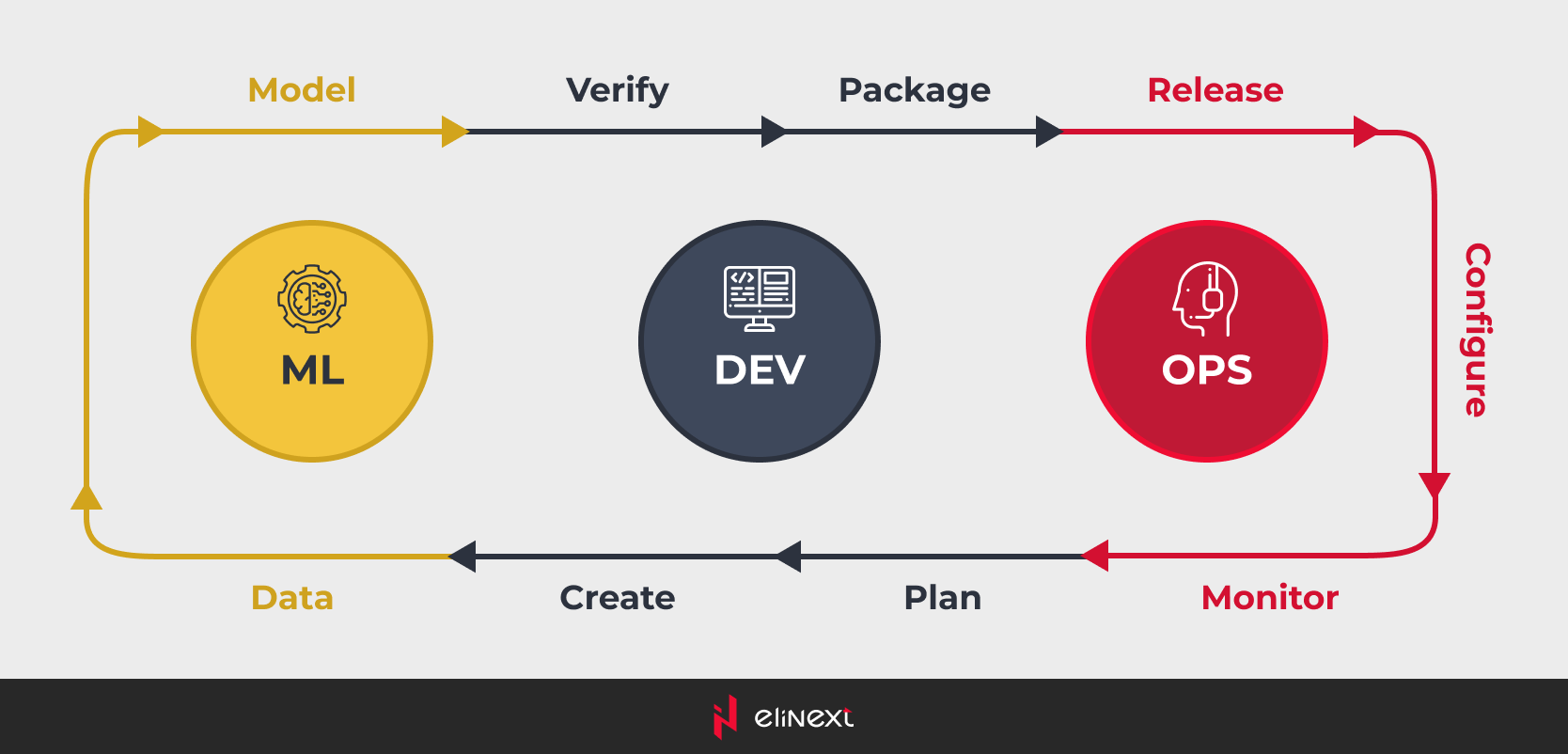
MLOps, short for Machine Learning Operations, is a set of practices that combines Machine Learning solutions and operations (Ops) to automate and streamline the entire ML lifecycle. It is inspired by DevOps principles, which aim to improve collaboration between development and operations teams in software engineering.
MLOps vs. Machine Learning
Comparing MLOps vs. ML engineering, we should note that they are related but serve distinct purposes in Artificial intelligence solutions. In practice, ML ensures development and training of models that can make predictions or decisions based on data. MLOps engineering, on the other hand, involves the tools and processes needed to effectively scale, monitor, and manage these models in real-world environments. MLOps solutions bridge the efforts of data scientists, ML engineers, and operations to streamline the entire lifecycle of ML models, from development to deployment and maintenance.
The core principles and practices of MLOps
What is important about MLOps vs. ML engineering, workflow orchestration is a key principle, ensuring that all steps in the ML lifecycle, from data collection to model deployment, are managed smoothly and effectively. At the same time, orchestration is a core component of MLOps, as it provides the framework for automating and managing the complex workflows involved in ML operations. The core principles of MLOps involve versioning for tracking changes in data, models, and code; reproducibility for validating results; collaboration between data scientists, ML engineers, and operations teams; continuous training and evaluation for maintaining models accuracy and relevance; monitoring and logging for tracking model; and finally, feedback loops for incorporating real-world data and insights back into the models.
By adhering to the following phases, organizations can efficiently oversee the entire MLOps lifecycle:
- Model Development: this foundational phase of building machine learning models involves key steps such as data collection and preparation, feature engineering, model selection, training, and evaluation to ensure the models are accurate and reliable.
- Preproduction: In this phase, the model undergoes testing and validation for real-world scenarios through validation on a separate dataset to check for overfitting, hyperparameter tuning to enhance performance, cross-validation for robustness, and A/B testing to compare the new model against existing.
- Deployment: this stage involves deploying the model into production through containerization to package it with dependencies using tools like Docker, implementing CI/CD pipelines for automated deployment, ensuring scalability to handle increased loads, and establishing rollback mechanisms to revert to previous versions if issues arise.
- Monitoring: this step is about This phase monitoring the model\s performance by tracking key KPIs, detecting drift to identify changes in data distribution that may affect performance, maintaining detailed logs for troubleshooting, and setting up alerts and notifications for anomalies or performance degradation.
Tools and Technologies
In the rapidly evolving field of machine learning, the MLOps solution market offers several tools to streamline and enhance the MLOps lifecycle. Here are some of the most popular ones:
- Kubeflow: An open-source platform designed to make deployments of machine learning workflows on Kubernetes simple, portable, and scalable. Kubeflow offers an extensive set of tools for developing, orchestrating, deploying, and managing scalable and portable machine learning workloads.
- MLflow: A free, open-source platform designed to manage the entire machine learning lifecycle. MLflow offers tools for experiment tracking, model versioning, and deployment. It is designed to work with any ML library, algorithm, and deployment tool.
- TensorFlow Extended (TFX): An end-to-end platform for deploying production ML pipelines. TFX provides components for data validation, model training, model analysis, and serving, making it a robust choice for production-grade ML workflows.
Tools comparison
When choosing an MLOps tool, it’s essential to consider the specific needs of your project and organization. Understanding the strengths and limitations of each tool will help you make an informed decision and optimize your machine learning operations:
Kubeflow
Pros:
- Seamless integration with Kubernetes, making it highly scalable.
- Comprehensive suite of tools for various stages of the ML lifecycle.
- Strong community support and continuous updates.
Cons:
- Steeper learning curve due to its complexity.
- Requires Kubernetes expertise, which might be a barrier for some teams.
MLflow
Pros:
- Simple to set up and operate, featuring an intuitive interface.
- Supports a wide range of ML libraries and tools.
- Flexible and can be integrated into existing workflows.
Cons:
- Limited built-in support for orchestration compared to Kubeflow.
- Some advanced features may require additional customization.
TensorFlow Extended (TFX)
Pros:
- Designed for production-grade ML pipelines, ensuring robustness and reliability.
- Strong integration with TensorFlow, making it ideal for TensorFlow users.
- Comprehensive components for data validation, model training, and serving.
Cons:
- Ideal for TensorFlow-based projects, though this may restrict its compatibility with other frameworks.
- Can be challenging for beginners to set up and configure.
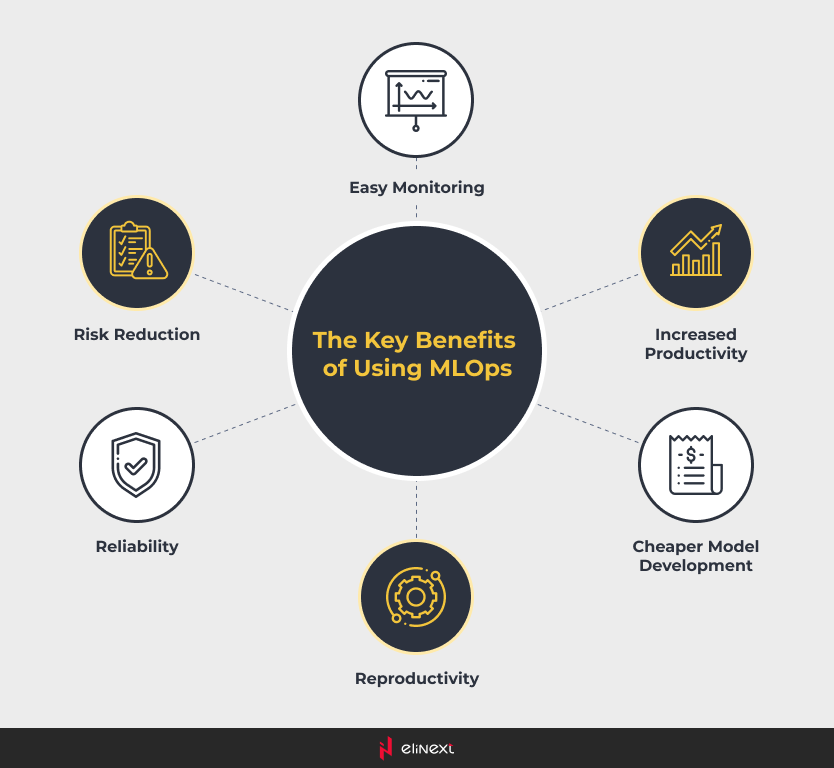
Main Benefits of MLOps Solutions
-
Creation of reproducible workflows and models
MLOps engineering standardizes processes like data preprocessing and model deployment, using version control for datasets and models to ensure reproducibility, crucial for compliance in healthcare and finance.
-
Easy deployment of high precision models in any location
MLOps solutions enable seamless deployment of high-precision models across diverse environments like cloud, on-premises, or edge. With CI/CD pipelines, they automate deployment, ensure consistency, reduce errors, and support real-time integration for scalable solutions.
-
Effective management of the entire machine learning life cycle
MLOps engineering unifies the machine learning lifecycle by integrating DevOps solutions, automating workflows, and enabling CI/CD/CT. It ensures seamless transitions from development to production, vigilant monitoring, and efficient updates for scalable, reliable models.
-
Machine Learning Resource Management System and Control
The benefits of MLOps also include efficient resource management by automating workflows, optimizing compute usage, and standardizing processes. MLOps engineering stands out due to control of model deployment, monitoring, and updates, reducing technical debt while enabling scalable, reproducible, and reliable ML systems.
Real-World MLOps Use Cases
Here, we explore some real-life MLOps Use Cases and respective lessons learned from organizations that have taken advantage of MLOps engineering.
Merck Research Labs
Merck Research Labs leveraged MLOps to accelerate vaccine research and discovery. By implementing automated ML pipelines, they significantly reduced the time required to develop and deploy models. This approach not only sped up research but also improved the reproducibility and reliability of their ML models.
Booking.com
Booking.com developed an in-house MLOps platform called Michelangelo to manage their extensive portfolio of ML models. This platform enabled them to scale their ML capabilities, growing their model portfolio by 150 times. The result was a more personalized user experience and improved operational efficiency.
AgroScout
AgroScout, an AI and computer vision solutions provider for agriculture, used ClearML’s MLOps platform to handle a 100-fold increase in data volume and a 50-fold increase in experiment volume. This implementation reduced their time to production by 50%, allowing them to deliver more accurate and timely insights to their clients.
EY (Ernst & Young)
EY adopted MLOps to accelerate model deployments and improve compliance with regulatory standards. By standardizing their ML workflows and automating deployment processes, EY was able to deploy models faster and ensure they met all necessary compliance requirements.
Starbucks India
Starbucks India applied MLOps to enhance their data-driven strategies. By integrating MLOps practices, they improved the accuracy of their sales forecasts and optimized inventory management, leading to better customer satisfaction and reduced waste.
MLOps Challenges & Risks
At the MLOps solutions market, deploying MLOps solutions can be challenging due to the complexity of integrating ML models into production environments. Organizations face issues like managing diverse tools, ensuring model reproducibility, and addressing scalability when transitioning from development to production. Data security is also among MLOps challenges, as sensitive information may be exposed during training or deployment. Moreover, a lack of standardized practices and the need for continuous monitoring and updates complicate maintaining model performance in real-world applications.
The Future MLOps Trends
Edge Computing and MLOps
Edge MLOps is at the top of future MLOps trends as the fusion of MLOps and edge computing empowers real-time AI at the edge. With models deployed closer to data sources, this reduces latency, enhances privacy, and ensures scalability. The future lies in automated workflows, edge model updates, and robust edge-AI pipelines.
AutoML Integration
Integrating AutoML into MLOps simplifies and automates the machine learning workflow, from data preprocessing to model selection and tuning. This combination accelerates model deployment, ensures continuous optimization, and democratizes AI by enabling non-experts to build robust models efficiently.
Explainability and Model Monitoring
Model monitoring and explainability will continue to be vital aspects of MLOps use cases, that help bridge the gap between opaque ML models and the visibility required by humans to understand and manage multiple dimensions of a model’s performance and inner workings.
Federated Learning and Privacy
As we look ahead, the synergy between Federated Learning and MLOps trends is set to transform the future of machine learning, reshaping its landscape in profound ways. We foresee a rise in federated architectures designed for specific industries like healthcare and finance, enabling data privacy while leveraging the collective power of distributed data. MLOps will play an even greater role, focusing on automating and optimizing every aspect of the ML lifecycle within a federated framework.
Integration with DataOps and AIOps
The integration of MLOps engineering with DataOps and AIOps will bring an additional value to streamlining and optimizing the lifecycle of data, machine learning models, and AI operations. Each of these disciplines plays a distinct yet complementary role in operationalizing AI and machine learning systems effectively thud forming a unified AI ecosystem. DataOps ensures quality data, MLOps builds models, and AIOps delivers insights. Inspired by DevOps, they boost agility, automation, and collaboration, optimizing AI pipelines for efficiency and reliability.
Conclusion
In this article, we shed a light on the MLOps lifecycle and best practices highlighting MLOps’ role in uniting ML development and operations alongside real-world success stories from the MLOps solutions market and globally known businesses.
As industries expect the software they rely on to be scalable, reliable, and efficient, software developing companies make efforts to hold ML models to these standards. Now, it’s time to bring that same level of optimization to machine learning through benefits of MLOps.
FAQs
How Is MLOps Different from DevOps?
While DevOps focuses on automating and optimizing the software development lifecycle, MLOps is dedicated to managing machine learning models, data pipelines, and their seamless deployment into production.
What Are Common MLOps Use Cases?
MLOps has proven its value across industries. Successful MLOps use cases cover accelerated vaccine research, risk assessment and compliance management in industries like finance and healthcare, ML models in production environment, etc.
How Does MLOps Improve Collaboration?
MLOps fosters collaboration by breaking down silos between teams, enabling efficient data sharing and workflow integration. This leads to faster model deployment and a streamlined ML process.
What’s the Future of MLOps?
The future of MLOps is associated with automation, scalability, fairness, and accessibility, enabling organizations to build reliable, ethical, and high-performing AI systems that drive meaningful outcomes.
