





How can you make Elasticsearch and your database work together seamlessly? Today, we’ll help you answer this question!
What is Elasticsearch?
Elasticsearch is a powerful tool for search and analytics, as well as a flexible data storage solution. It is based on the Lucene engine, enabling fast and efficient searches within vast datasets. If you have a website or application and wish to provide users with a fast and convenient search experience, Elasticsearch is an excellent choice.
Numerous major companies, enterprises, and agencies all trust this tool. NASA employs Elasticsearch for processing and analyzing technical data. IBM integrates it into its cloud solutions. Uber uses it to handle geospatial data, while The New York Times leverages it for instant searches across its extensive article database.
So, why do we need to integrate Elasticsearch with other databases, and why not use Elasticsearch as the primary data storage? In many cases, Elasticsearch can serve as the main storage solution, providing quick access to information and efficient indexing. However, it might not always be the ideal solution for specific tasks. For example, Elasticsearch is not designed for transactions like relational databases or for storing graphs like graph databases. By combining Elasticsearch with other data storage systems, you can leverage the best features of each technology. This will allow you to provide instant search with Elasticsearch and, at the same time, ensure reliable and efficient data storage in your main database.
In this article, we will explore some of the ways to integrate Elasticsearch with databases.
How Can We Integrate Elasticsearch with Databases?
Logstash
Logstash is a server-side tool in the ELK stack (Elasticsearch, Logstash, Kibana) that provides processing, transformation, and direct delivery of logs and events from various sources to Elasticsearch. Its primary purpose is to simplify data integration.
One of the essential features of Logstash is its plugins. With input plugins, you can extract data from different sources. For example, if you have a PostgreSQL database and you want to transfer data from there, a Logstash configuration might look like this:

There are also plugins for NoSQL databases, such as MongoDB. Here is an example of how that can be configured:

After extracting the data, Logstash begins processing it using various filters. These filters can change the data format, enrich it, and more. For example, to alter the date format from “YYYY-MM-DD” to “DD/MM/YYYY,” you can use the following filter:

Once all the transformations are complete, the data is ready to be dispatched. For example, to send data to Elasticsearch, you can use the following configuration:

What makes Logstash unique? Its flexibility — you can configure it as needed, thanks to the many available plugins. Moreover, setting up the extraction, processing, and data dispatching process becomes easier with configuration files. It’s also scalable and can handle substantial amounts of data, making it an excellent choice. However, keep in mind that Logstash can be resource-intensive. Also, while it offers many capabilities, it may sometimes require experience to set up and use effectively.
Kafka
Apache Kafka is a streaming data processing system that provides fast, reliable distributed storage and real-time transmission of vast amounts of data. In modern IT infrastructure, Kafka is often an essential component, processing millions of events every second.
To successfully integrate data from your database into Elasticsearch using Kafka, start by establishing a connection between your database and Apache Kafka. The Kafka community has developed various connectors and plugins for different database types. These tools monitor changes in your database, often using the Change Data Capture or CDC mechanism, and automatically stream these changes to Kafka topics.
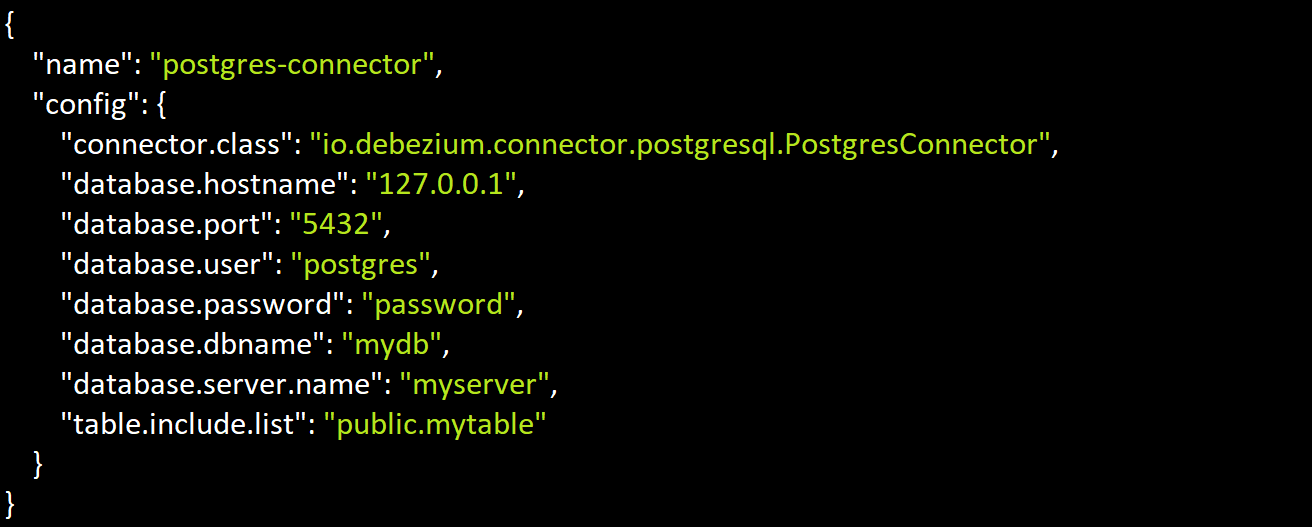
Let’s assume you are using PostgreSQL or MongoDB databases. For PostgreSQL, it is recommended to use the Debezium connector. This connector tracks changes to your database and pushes them to the appropriate Kafka topic:
For MongoDB, you can use the MongoSourceConnector:

Once the data has entered the Kafka topics, the next step is to prepare and optimize it for further integration into Elasticsearch. Tools like Kafka Streams and Kafka Connect Transformations (Single Message Transforms) provide the possibility for efficient data transformation, adapting it to the specific needs of Elasticsearch.
Finally, using the Kafka-Elasticsearch connector, data is automatically indexed from Kafka topics directly into Elasticsearch, ensuring their relevance and real-time synchronization.

So, what are the primary advantages of integrating Apache Kafka and Elasticsearch? The main benefits include real-time data processing and resilience. Kafka ensures continuous information integration, particularly relevant in scenarios where fast and reliable data updates are crucial. Thanks to its distributed architecture and data replication, Kafka also guarantees continuous system operation even when individual nodes fail.
However, it’s essential to keep in mind that the implementation and support of Kafka require a deep understanding and can be challenging. Moreover, supporting additional infrastructure might increase costs. Nevertheless, for large-scale streaming architectures where continuous data transmission is critical, Kafka is often chosen as the preferred tool.
Triggers and Listeners
Direct integration with Elasticsearch provides an efficient method for data synchronization. Without intermediary steps or additional layers, changes from your database are quickly relayed to Elasticsearch, making data processing and analysis easier.
In cases where SQL databases such as PostgreSQL are used, trigger mechanisms at the database level are actively employed. They track any data changes and generate alerts. These alerts can be intercepted by listeners in your application. These listeners process the notifications and send the corresponding updates to Elasticsearch.

For MongoDB, there is a feature called Change Streams. This functionality allows applications to view and react to data changes in real time. Change Streams provide streaming access to the full record of changes, including information on what data was altered and context about these modifications.
However, such an approach may introduce additional strain on your database. Moreover, if Elasticsearch becomes temporarily unavailable, there is a risk of data loss since there is no intermediate storage or resend system. Thus, while direct integration does have certain advantages, it may not be suitable for all cases, especially when stability and scalability are paramount.
In conclusion
Integrating with Elasticsearch can be a challenging task, but armed with knowledge and the right tools, you can achieve excellent results. As you have learned from this article, there are multiple integration approaches, and each has its advantages and peculiarities. Nevertheless, this is not the entire list of potential methods, and other strategies might be employed in practice depending on your specific needs and system architecture.
We hope this article serves as a starting point in the world of integrating with Elasticsearch. Don’t hesitate to experiment, to always seek new, more optimal solutions. We wish you success in integration!
