





Sometimes database migration may become a pain. The tables are large, the load is high, HDD space is expensive and the downtime should be as short as possible. Elinext team has recently investigated the issue within one of our Ruby on Rails projects and managed to offer a flexible data migration strategy.
The challenge started with a migration of the high-load table containing 2+ billion rows where we needed to change data type for a primary key of the table. The ultimate goal of the client was to develop the solution allowing to make any changes to the tables, modify data on the fly, monitor HDD space taken by the database, and log the migration process.
With that in mind, we set the following requirements for database migration:
- Full accessibility to all the data during the entire migration process for read, write, delete and update.
- Shortest downtime possible.
- Minimum of data duplication (no database copies or full copies of the migrated table).
- Migration triggered and controlled from the web-framework.
- No changes to the existing framework code – only some additions related to the migration triggering and monitoring. No additional deploys needed during the entire process.
In an attempt to find a solution, we tried several options but all of them were blocking the table or the database for longer than we could afford. So we decided to try another approach. The general idea was to have three tables and toss the data between them in the background without duplication. Let’s see what we’ve got:
- The first table (‘old’) is the actual old table with lots of rows.
- The second table (‘new’) copies the structure of the ‘old’ table, but has the required modifications (bigint primary key in our case). This table is the resulting one, it will store the data and remain in the system after the migration is finished.
- The third table(‘temp’) is used to handle ongoing inserts, updates and deletes caused by users. Its structure copies the ‘new’ table.
The actual background job moves (not copies) data from the ‘old’ and ‘temp’ tables to the ‘new’. As a result, the ‘new’ table becomes very slow for inserts coming from users (web framework side). So we use ‘temp’ table to serve the ongoing inserts from the web-server. The ‘temp’ table is not loaded by the migration, that is why the overall performance remains at a good level.
In addition, SQL views and functions are used to emulate behavior of the old table for the web-framework (RoR in our case). Views are acting as an adapter between web-framework (which acts as if it still communicates with the old table) and the actual three tables in database.
Below is some PostgreSQL code we used to create all necessary tables, functions, and views. This code has been initiated from a rake task manually as soon as we decided to start the migration. It goes without saying that transactions should be used where necessary to make the flow more safe.
- Create the new table, modify it and rename the old one:

- Create the view to emulate the ‘cars’ table behavior on SELECT queries from the web-framework:

- Set the next id value for ‘cars’ to the current cars id sequence.

- Create a function to handle the insert, update and delete actions coming from the web-framework:

- Create the trigger to redirect the calls to ‘cars’ table to the function created above.

When this code is initiated, the framework should work as it always does. But the SQL server will write the new data to the ‘temp’ table with id starting right after the last id in the old table. And the SELECT calls will gather items from the three tables.
Our next step is the actual data migration. For this purpose, we create a background job. It can be run manually, using a schedule, directly after initiating the SQL code above etc. The main task of this job is to move data from ‘old’ and ‘temp’ tables into a new one with the changes you need. To optimize the process, our team suggest using stored function and call it from the job (instead of forming the entire SQL on the framework side again and again). Here is an example of such a function:
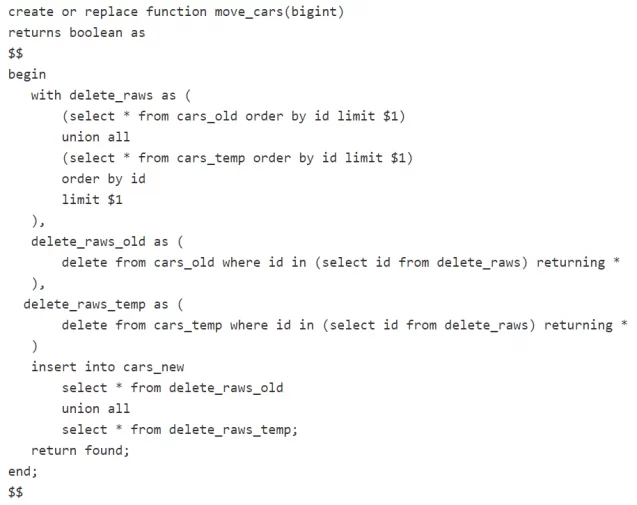
This function can be called from a job like this: SELECT move_cars(10000);
There is a possibility of adding any additional logic to the job. For example, we called VACUUM CLEAN and ANALYZE once to optimize the database size. We also added some logging to track the progress.
When the migration is finished, it is time to clean up. We need to drop the view, delete the functions and swap the tables. The following actions were done:
- Open a transaction.
- Call the sync function one last time to make sure no data is lost. (‘SELECT move_cars(10000000);’)
- Execute the swap and cleaning code.
- Close the transaction.
And here is the swap and clean up code:

And this is it. The full migration took us about two months. And the downtime was about 10-15 seconds, spent mostly on servers restart. Database size was not wasted due to VACUUM command. No additional deploys were done – the framework code was intact. We reached all the requirements using this approach.
