





There once comes a time when every well-growing project starts to require more resources than a usual desktop server could produce. This is the right time to think about scalability.
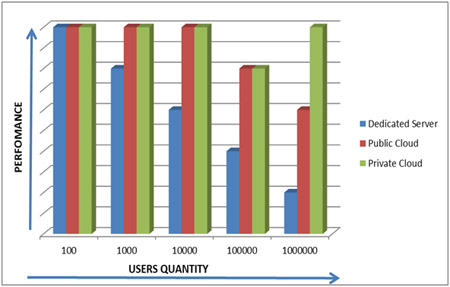
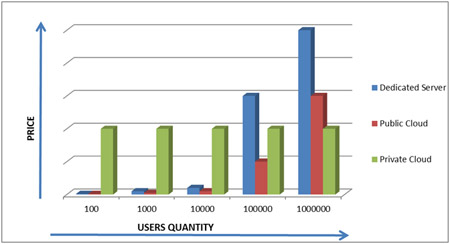
Before reading the article, we would like to show you two price and performance dependency charts for different hosting solutions related to the number of users of the project.
In this article, we will talk about the Public Cloud related to Microsoft Azure, as a most price/performance balanced solution for all types of projects. But before choosing it, it’s worth reviewing which hosting solution will best fit your project needs.
So let’s go back to scale.
There are two techniques for scaling the hardware resources: scale-up and scale-out.
- Scale-up is a technique for the hardware upgrade of the current server or moving to a stronger one. For example, you could change a usual desktop PC to the Professional Server solution with 8 CPUs. This technique is preferable for not very big projects.
- Scale-out is a technique of splitting the resources into several server instances. To split the requests queue to all the instances in the network (cloud), all huge projects, like Facebook or Google, use scale-up techniques to process all the requests to their services.
Scaling up has a lot of positive sides for big projects. First of all, the size of the cloud is not limited. You can start from only a few units and then add more and more. But remember! You should foresee this situation on the first architecture phase of the project and design a multithread architecture, so the requests could be easily balanced between hardware instances. Because if you try to move to a cloud application that uses only one core of your CPU, this will give you no performance benefits at all. The other positive side of scale-out is money. A 64 CPU server is much more expansive than 64 units with one CPU.
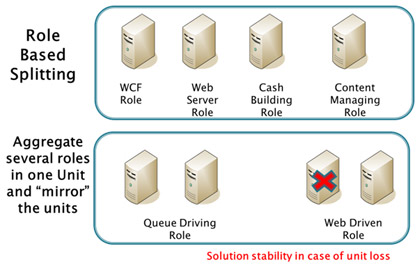
Scaling out also has different ways of implementation. You could split the tasks between the instances according to the roles or you could group the roles and set up several units with the same responsibilities to achieve a mirroring effect (see the picture).
In Windows Azure Cloud Solution Virtual Machine (VM) there is a unit of measurement. VMs could be of different sizes as you can see in the table below.
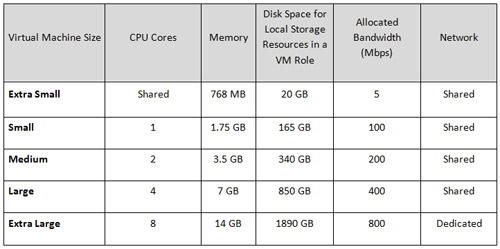
You could easily change the VM size in the service definition configuration file (*.csdef) by setting the vmsize attribute. <WebRole name=”WebRole1″ vmsize=”Small”>; </WebRole>
Before setting the VM size for production, it is useful to test different configurations. It’s no use setting Extra Large instances for all the task types. Different tasks also require different resources. Tasks like video encoding require a high CPU load, but tasks like Database Server require more bandwidth.
Caching is a good pattern to reduce the resource requirements and, as a result, save your money. Cache implementation is a good way to minimize the traffic, the number of storage transactions, and database requests. It could prevent the loading of static images used in UI or the RSS data collection. These are two more regular examples of unneeded load generation that depend on client activity.
There are two different ways of caching implementation available for Windows Azure:
- Client-side caching;
- Static content generation.
Client-side caching is a technique of caching that uses the client-side browser. There are also two ways of implementation:
- Using E-tags (special meta tags in the page header). This method is natively supported by Azure Storage.
- Cache-control is a good possibility to store user content without update up to 30 days. It is good for big static files.
Static content generation could be done for full pages, CSS files, or any generated resource files. Dedicated workers could be assigned for the content generation and upload to the blob storage. In this case, static content will be generated only once, which will save a lot of money on transactions to Azure Storage and bandwidth.
Elastic scale-out is required when you don’t know how much resources you need, or the load is changing according to the predictable rules (for example, day and night load on the news portal, or the higher load on the online store portal during the sale). You can see general load patterns on the graphs below.
You can deal with the variable load in two different ways, depending on your budget and needs:
- Maintaining excess capacity when you work with maximally needed hardware resources, and tear down only some of them when they are not required. In this case, you could almost immediately remove resources, but you won’t save any money, because you will need to pay even for the turned off instances.
- Turning off/on instances will allow you to save money, but it will require time for just added instances to get ready.
You could also set up rule-based scaling when you use metrics to predict the server load or use the time table for managing hardware resources in the automated mode.
Metrics used for the calculation of the server load could be organized into three groups:
- Primary metrics: requests per second, queue messages processed.
- Secondary metrics: CPU utilization, request queue length, server response time.
- Derivative metrics: rate of change of the queue length and historical load statistics for prediction.
You can collect statistics from the .Net code using Microsoft Azure Diagnostics namespace tools, or use other statistic sources like Event Log, IIS Logs, Infrastructure Diagnostic Logs or built-in performance counters. And always think about the price of measuring. Measuring everything may spoil your performance achievements.
So before you start thinking about your business needs, take into account the following:
- Do requests take too much time for processing?
- Could the performance problems be resolved by the project refactoring or it really needs scaling?
- How much money could you spend on scaling?
And only after that you could start implementing automated scaling using the Management API or by changing the size of the instance in the service configuration files (*.csdef). You could also create a mechanism of performance problems notification or make a rule set for scheduled scaling.
And remember. It’s better to use all the code related possibilities, like caching or code optimization, before adding the new instances to your system. Only smart scaling will increase your project performance, and every cent you spend on it will give you a good result.
Industries and Technology Areas:
Industries: cloud computing, Microsoft Azure, software development
Technology Areas: Microsoft Azure, scaling techniques, caching, .Net, software development
