




By 2025, AWS stream processing big data solutions will power 71% of cloud streaming platforms, reaching a market size of $11.26 billion. AWS development company helps enterprises leverage Amazon Kinesis for real-time analytics, reducing data latency from hours to minutes. Yelp’s migration to AWS reduced data storage costs by 80% and enabled access to information in minutes. AWS’s serverless architecture and global reach drive innovation, scalability, and operational efficiency in the financial, healthcare, and media industries.
Elinext: Leading Experts in Cloud Engineering Services
Elinext excels in serverless Kinesis data analytics and cloud application development services. They have built a real-time analytics platform using Kinesis Data Analytics, enabling clients to process millions of events per day with sub-second latency. Their expertise enables seamless integration, elastic scaling, and secure data pipelines, enabling enterprises to gain actionable insights and drive digital transformation with AWS cloud solutions.
Four Core Services of Amazon Kinesis Is Divided
Big data stream processing on AWS is accomplished using four core Amazon Kinesis services: Video Streams (for secure video ingestion), Data Streams (for real-time structured data), Data Firehose (for automated delivery to storage/analytics), and Data Analytics (for real-time SQL/Flink analytics). Together, they provide scalable, serverless, and comprehensive streaming data solutions for a variety of use cases.
1. Video Streams
Video Streams makes it easy to securely stream video from connected devices to AWS for analytics, machine learning (ML), and other processing. AWS stream processing big data with Kinesis Video Streams enables secure and scalable video ingestion and storage. Smart city cameras use Video Streams for real-time surveillance and analytics, integrating with AWS AI for object detection and event monitoring.
2. Data Streams
Data Streams is a scalable and durable real-time data streaming service that can continuously capture gigabytes of data per second from hundreds of thousands of sources. Big data stream processing with Kinesis Data Streams ingests gigabytes per second from multiple sources. Disney+ uses Data Streams to analyze clickstream data in real time, providing recommendations and actionable insights at scale.
3. Data Firehose
Data Firehose is the easiest way to capture, transform, and load data streams into AWS data stores for near real-time analytics with existing business intelligence tools. Serverless Kinesis Data Analytics and Data Firehose automate the delivery of real-time streaming data to S3, Redshift, or OpenSearch. Nerdwallet uses Firehose to seamlessly load analytics data into AWS for instant reporting and business intelligence.
4. Data Analytics
Data Analytics is the easiest way to process data streams in real time with SQL or Java without having to learn new programming languages or processing frameworks. AWS stream processing big data with Kinesis Data Analytics enables real-time streaming data analytics using SQL or Flink. VMware processes 1 PB per day for instant anomaly detection and actionable insights, all in a serverless environment.
Get access to real-time analytics and business agility and invest in big data stream processing with Amazon Web Services to drive innovation, efficiency, and competitive advantage!
Common situation
Usually, if spec for a project does not require architecture to deal with high loading, this aspect often gets overlooked. This is especially true in cases when budget and time frame for development are limited.
In most cases. incoming data goes directly to the app, which processes it, does certain actions and stores the data into the database. Everything works fine until the “sudden popularity” hits the project, and the collected amount of data becomes too large for the processing.
Then the app begins working way too slowly and consumes a lot of memory. Parts of incoming data usually get lost.
Often first counter-actions taken against it are upgrading the hardware and doing some code refactoring. It helps for a certain period of time, usually for a day, or two. Then incoming data increases 100x times and transfers into millions of requests a day and gigabytes of data.
The thing that could help now is upgrading the architecture to the one that can handle high loading. KinesisStream service will be considered as one of the possible ways to achieve it. We’ll give you the pros and cons of using the service below.
Architecture without KinesisStreams
First of all, we have to mention that only some common approaches improving different processes will be reviewed. Let’s begin with analyzing the main issue in detail.
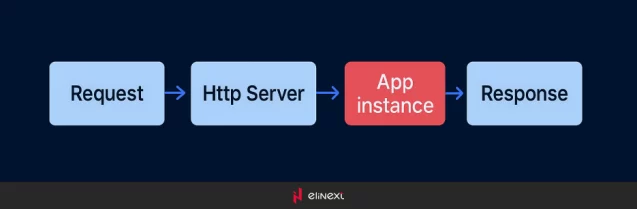
The HTTP server creates a process in the system, i.e. Ubuntu for dealing with requests. The process consumes CPU time and memory. Then another request comes at the same time and it has to be processed as well. The more an App instance needs CPU and memory, the fewer requests can be handled by the server.
Oftentimes, only one instance can consume all the CPU time and all the memory. When we talk about the millions of requests, updating the hardware or moving to the cloud is often too expensive of an option.
Let’s have a look at the situation inside the App instance. Processing a request usually goes in many steps. Most of the steps work fast and do not require optimization. Several other steps do depend on some conditions.
Those conditions are incoming data or data from the database that need to be processed. These steps, should they work really slow, block the other steps from operating with the normal speed. So we have to do something with the problematic steps that slow the pace.
Reading and writing from and to the database
The problems might occur while reading from the database and writing to it. In respect of hundreds of gigabytes of data, these steps can be a headache. The queries have to be optimized.
If not, well, just FYI, 1 non-optimized second of waiting becomes 11 days of waiting for a million requests.
Separating reading and writing operations using database replication is a good solution to the problem. If the readable data is not very sensitive to a fresh state, the replica will increase the performance dramatically.
After that, it could be useful to cache complex queries selection and calculation results. The latter could be simply stored in memory. Regarding complex queries, there could be difficulties on the way.
As for databases, there could be such a mechanism as views that can hold the pre-selected rows. Thus it simplifies selection for us.
Moving data to a specific database
Specific databases are designed for doing specific things. Thus, selecting the correct database for storing and operating part of app data could significantly improve the performance.
For instance, ElasticSearch can be considered for searching for some documents, ClickHouse is great for keeping data for statistics, and Reddis works perfectly for storage of the pre-selected cached results.
We could go on with specific databases (as there are plenty), but this is a topic for another article.
Splitting App execution steps into microservices
This is by no means an easy process for the existing apps. However, it is worth the try as microservices handle high data loading very well. Slow steps are moved to the background from the main execution chain or being scaled with the additional resources. We’ll review this approach in detail in the context of Kinesis DataStream.
Architecture using Data Streams
In this architecture, all the data collection will be handled by DataStream. It is not required to split all the steps into microservices as we can do the data processing step only.
For this, we need to implement Provider and Consumer for our DataStream to put in and read the data accordingly.
Now, the steps will look like that:

In this diagram, the Provider is the App instance, which uses the AWS SDK internally to send the data.
Once the data is sent, the response can be returned. There is no need for us to wait for the data processing step to end. Thus, we have solved the main problem, which was moving the slow step out of the main chain of steps.
But what about DS? How does it handle a big amount of data? To control the throughput, DS uses so-called shards. The official Amazon documentation explains it as follows: “A shard is the base throughput unit of an Amazon Kinesis data stream. One shard can ingest up to 1000 data records per second, or 1MB/sec. To increase your ingestion capability, add more shards.”
So we can control the throughput by adding or removing shards depending on the level of data load.
And now, it is up to Amazon to provide the required capacity for this step.
So the data in a DS. But it still needs to be processed. For this step, we need to create a Consumer.
It can be a piece of code that constantly gets stored in DS data and processes it. The more interesting solution is to add the Lambda function that will do all the processing. Once data comes, the function is triggered. Thus, both storing and processing operations are moved to Amazon services with auto-scaling.
What kind of data can use this approach?
Pretty much any data that doesn’t need to be returned to the user as a response.
Here is a nice example when it could be useful. The app collects large amounts of data for statistics which needs to be analyzed, compacted and stored into many tables in the database. Such operations can be time-consuming and it is better to do it in the background. That is achieved thanks to the DS service.
Architecture using Data Firehouse
It is pretty much the same. The only difference is that instead of a consumer, we use one of Amazon’s data storages (S3, Redshift, Elasticsearch, and Splunk).
So, if you need to process and store images or logs on S3, you send it to a DF and it will be done in the background. The App would not have to be waiting for this operation to proceed.
You might wonder, how can it do all the processing if DS just sends the data to one of the storages?
Like in the case with DS, Lambda function can be added to the pre-process before storing it.
Any sample?
First of all, you need to create a DataStream in your AWS account. It is fairly simple, just open Kinesis service in the AWS console, click the “create” button and Amazon will guide you through the process.
Also, you can check the official guide to read about the available options. Once done, you can use the code below to play with it.
Provider ( PHP ) :
require ‘vendor/autoload.php’;
use Aws\Credentials\CredentialProvider;
use Aws\SecretsManager\SecretsManagerClient;
use Aws\Kinesis\KinesisClient;
use Aws\Firehose\FirehoseClient;
$profile = ‘default’;
$path = ‘aws/credentials’;
$provider = CredentialProvider::ini($profile, $path);
$provider = CredentialProvider::memoize($provider);
// Kinesis DataStream case.
$client = KinesisClient::factory([
‘version’ => ‘latest’,
‘region’ => ‘us-east-2’,
‘credentials’ => $provider
]);
$result = $client->putRecords(array(
‘StreamName’ => ‘MyFirstKStream’, // name of a stream you have created.
‘Records’ => array(
array(
‘Data’ => uniqid(), // data to send.
‘PartitionKey’ => ‘shardId-000000000000’,
),
),
));
// Kinesis Firehose case.
$client = FirehoseClient::factory([
‘version’ => ‘latest’,
‘region’ => ‘us-east-2’,
‘credentials’ => $provider
]);
$result = $client->putRecord(array(
‘DeliveryStreamName’ => ‘MyFirstDStream’, // name of a stream you have created.
‘Record’ => array(
‘Data’ => uniqid(), // data to send.
),
));
Consumer ( Lambda node.js ) :
console.log(‘Loading function’);
exports.handler = async (event, context) => {
let success = 0;
let failure = 0;
const output = event.records.map((record) => {
/* Data is base64 encoded, so decode here */
// const recordData = Buffer.from(record.data, ‘base64’);
console.log(record);
try {
/*
* Note: Write logic here to deliver the record data to the
* destination of your choice
*/
success++;
return {
recordId: record.recordId,
data: record.data,
result: ‘Ok’,
};
} catch (err) {
failure++;
return {
recordId: record.recordId,
result: ‘DeliveryFailed’,
};
}
});
console.log(`Successful delivered records ${success}, Failed delivered records ${failure}.`);
return { records: output };
};
Accelerate your data journey!
Leverage serverless Kinesis data analytics for real-time decision making and scalable cloud solutions with AWS to ensure your business resilience today!
Business Value and Future of Big Data Stream Processing with AWS
AWS stream processing big data and SaaS App Development Services, delivering measurable ROI up to 10% cost savings and 5-10x performance improvements. A logistics company using AWS Kinesis and SaaS applications automated real-time tracking, reducing latency and increasing customer satisfaction. As AI and analytics advance, AWS will continue to deliver predictive power, global scalability, and secure, compliant data operations for any industry.
As cloud experts, we view big data stream processing as the foundation of digital transformation. Using AWS and our cloud engineering services, we help customers build scalable, real-time analytics platforms that drive more informed decisions, operational efficiency, and business growth in today’s data-driven world.
Elinext Expert
Conclusion
AWS stream processing big data depend on robust security. The AWS Key Management Service (KMS) encrypts data at rest and in transit, ensuring compliance and privacy. A healthcare provider using KMS with Kinesis Data Streams achieved HIPAA compliance while processing patient data in real time. AWS KMS seamlessly integrates with all Kinesis services, providing centralized, automated key management for secure and scalable analytics.
FAQ
What is stream processing in the context of big data?
Serverless Kinesis data analytics enables real-time processing of massive data streams. IoT sensors stream live metrics for instant analysis.
Why is stream processing important for big data?
Big data stream processing delivers instant insights. Banks detect fraud in real time, preventing losses and improving customer trust.
Which AWS services are commonly used for stream processing?
Big data stream processing uses Amazon Kinesis, MSK, Lambda, and S3. Kinesis Data Streams powers real-time analytics for media apps.
How does Amazon Kinesis support stream processing?
Amazon Kinesis ingests, processes, and delivers streaming data. It enables real-time clickstream analytics for e-commerce platforms.
How is real-time processing performed on AWS?
AWS uses Kinesis Data Streams, Lambda, and Data Analytics for real-time processing. Retailers analyze sales events instantly for promotions.
How is stream data stored for long-term analysis?
Stream data is stored in Amazon S3 for long-term analysis. Yelp archives streaming logs in S3 for historical trend analysis.
Is stream processing secure on AWS?
Yes, AWS encrypts data and uses IAM for access control. Financial firms use AWS KMS to secure sensitive transaction streams.
